
by Zsolt Katona
Over the years of teaching I found that the best way to prepare is to watch a video recording of the same session from the previous year. Lately, I realized that the automatic videotaping setup in our new classrooms not only records the presenter (instructor), but also the audience (students). That’s when I had this idea of using some of the new flashy computer vision tools to analyze the images. Why not use Google’s Cloud Vision tool, for example to detect faces and emotion? After feeding a couple of quick trial images into the tool, and seeing the objectively detected joy on my student faces, I got excited and my head started filling up with all sorts of ideas. I could automatically analyze facial expressions, identify which parts of the lecture are exciting, which parts are boring, and update accordingly. Perhaps automated measures of student engagement could substitute for the oft maligned student evaluations conducted at the end of every semester.
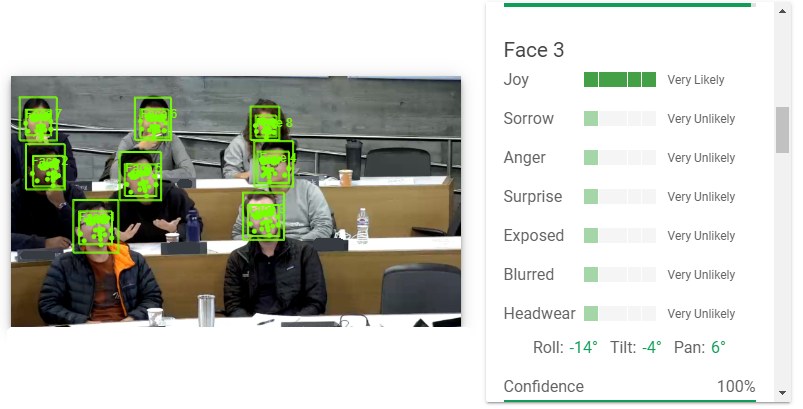
I almost got to the point of bringing the idea up to my colleagues when I processed the following image:1

1 I would like to thank the students who are visible and recognizable in the images for their consent to use their photos
The problem cannot be more obvious: the algorithm automatically detected the face of every student in the image except for the one African American student. I then searched for an image with another African American student in my marketing class and discovered the same problem. To be clear, I did not do any comprehensive analysis and I did not compare this facial detection algorithm with other publicly accessible implementations; but the only faces that were missed in two classes numbering over one hundred students were these two. That is staggering, as the algorithm missed two thirds of the African-American faces and found nearly all of the rest.

So what should one do? Clearly, we will not use this technology for analyzing classroom interactions in the near future, but there are some implications. For all the talk of algorithmic bias, in supervised machine learning, biased outcomes are often the result of imbalanced training data rather than something inherent to the algorithm itself. I am of course not the first one to discover these problems, there is more and more research into this area. If you want to learn more, there are great articles about bias in face detection, classification and a new large-scale effort to compare facial recognition algorithms.
But who is responsible here? I usually recommend that anyone who trains an algorithm watches out for unwanted bias. So if you train your own algorithm, you are on the hook for checking your training data and evaluating the results. But what if you don’t train your own algorithm and just use an off-the-shelf solution that has already been trained? There are a plethora of paid services and open source packages for computer vision including face detection and facial recognition. In an ideal world, at least the paid services should test and certify their algorithms against commonly encountered biases. But we are not in an ideal world, and as seen in my example, even big prestigious players like Google may put tools out there with obvious flaws. Thus one needs to vigorously look for the possibility of bias and proactively test for it, especially when using off-the-shelf solutions.
Update 2/25/2020:
Two days after publishing this article, the Google Cloud Vision team reached out and acknowledged and identified the problem. Apparently their API did not use the most up-to-date face detection model version. Another four days and the API was updated! I did not do extensive testing, but I did try the two images above and all faces are now detected regardless of skin color.